Dailymotion is more than a video application, it’s a visual conversation in motion, based on a unique algorithm designed to broaden users’ horizons instead of locking them in their own bubbles. We bring nuance to the debates that animate young people and put listening, discovery, and kindness back at the heart of interactions to help build a better and safer Internet.
Explore our Job OffersOur Mission
We build the next generation of media platforms designed to inspire millions of people to grow and share a diverse and inclusive vision of the world.
400M
4B
145
35
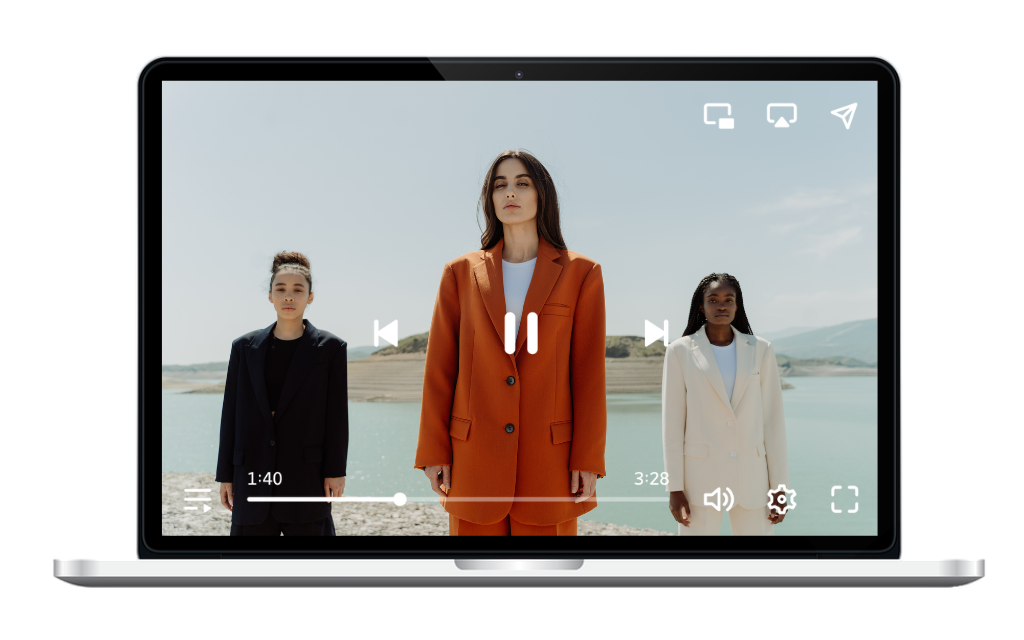
Dailymotion Advertising is a powerful, proprietary video advertising platform, offering a high-quality, secure environment for brands.
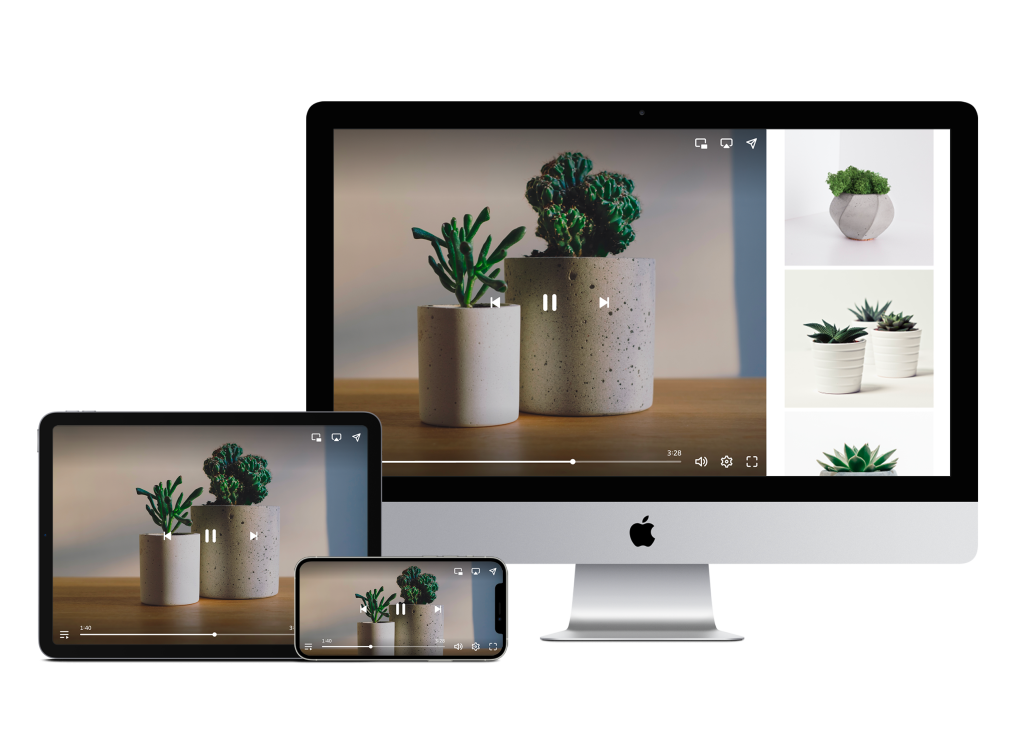
Dailymotion for Enterprise is a video hosting and broadcasting solution for professionals in all sectors.








